OLTP on seven engines, OLAP on three — addressed natively.
The operational application is portable across seven relational engines — PostgreSQL, Informix, Oracle, DB2, SQL Server, MySQL and SAP HANA. Analytical workloads route to three OLAP engines — Vertica, ClickHouse and BigQuery. Native SQL generation across all ten — engine-native syntax, dialect, sequences and quirks emitted by the compiler, not a generic dialect the engine has to translate. A schema compiler that imports, sequences and modernises existing estates without translation. The data tier is engineered to a depth most platforms reserve for the application tier.
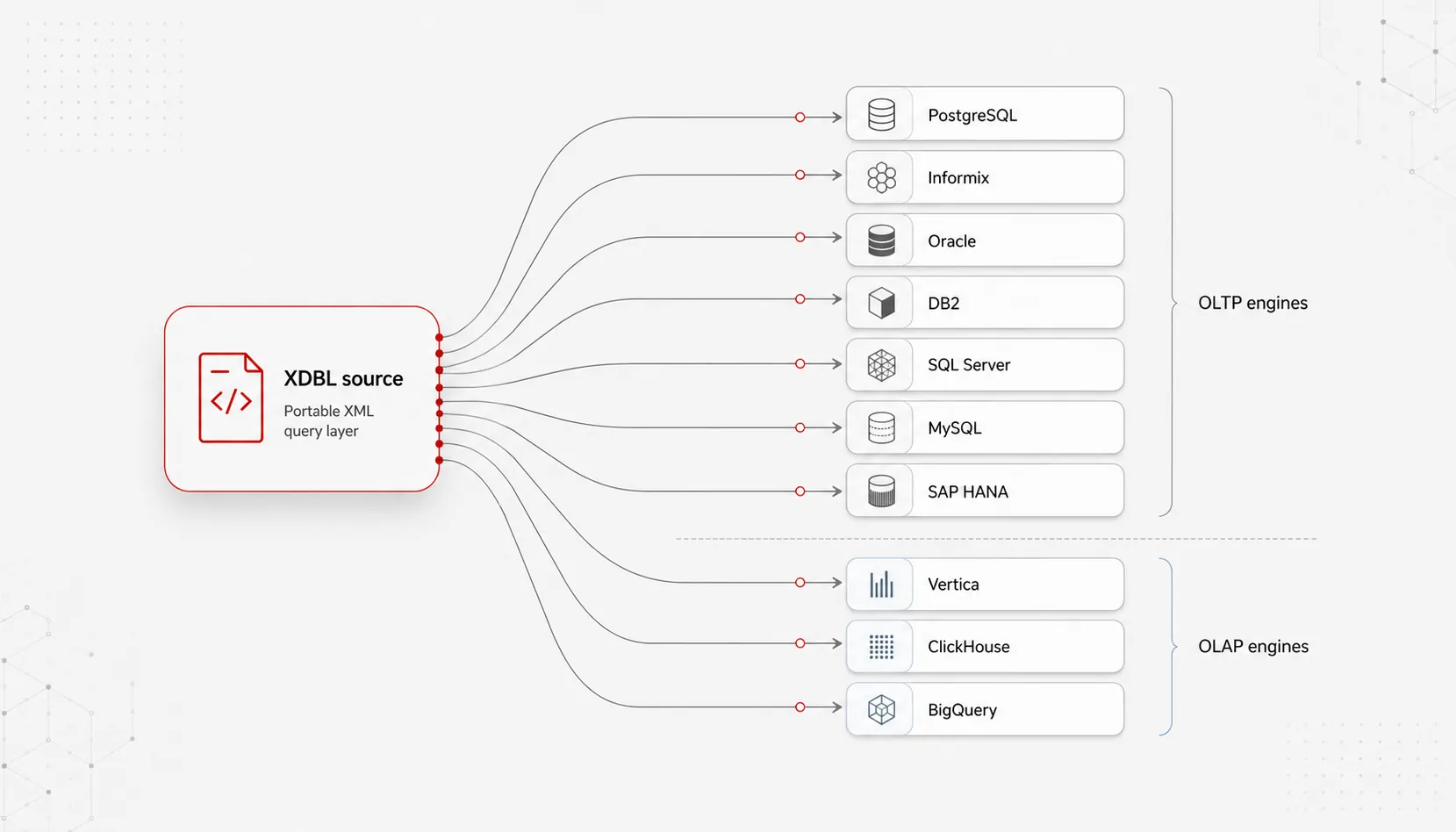
Ten engines, native SQL on each
Native SQL generation across all ten supported engines — engine-specific syntax, dialect, sequences and quirks emitted by the compiler. No generic dialect for the engine to translate at runtime.
OLTP application source, OLAP analytical back end
The same operational application runs on one of seven OLTP engines (PostgreSQL, Informix, Oracle, DB2, SQL Server, MySQL, SAP HANA). Analytical workloads route to one of three OLAP engines (Vertica, ClickHouse, BigQuery). Both sides share the same compiler.
XDBL — XML in, native SQL out
A database-independent XML grammar for DDL, DML, DCL and SPL. Write the schema and the procedures once in XDBL; the compiler emits native SQL for any of the supported engines — date arithmetic, string functions, sequence handling and dialect quirks resolved automatically. AI-targetable by construction, because the grammar is XSD-described.
Schema compiler with import
The customer's existing schema is imported as-is into the metadata repository. Tables, indexes, constraints, stored procedures and triggers ported by recompilation, not by hand.
OLTP — seven supported engines, native SQL on each
The application runs on the engine the workload deserves. The application code does not change when the engine does — the compiler emits the engine-native SQL for each.
PostgreSQL
The default modern target. Open, deeply tested with the platform, full Tier-1 DBA depth from our team. Logical replication and CDC streaming to the analytical tier (Vertica, ClickHouse) supported natively. First-line recommendation for greenfield deployments and most modernisations.
Informix
The deepest engine in our practice. Data blades, Java extensions, CDC streaming, full Tier-1 DBA depth. The right answer when the customer's existing estate is on Informix or when the operational profile favours its strengths.
Oracle
Full schema, PL/SQL, package and job-scheduler support. Tier-2 development depth on our side; the customer's existing Oracle DBA practice owns operations. Common in Oracle Forms modernisation programmes.
DB2 · SQL Server · MySQL · SAP HANA
Supported as targets where the customer's existing estate or licensing landscape requires. Tier-2 development depth — full application engineering, with DBA-grade operations referred to vendor or partner. See airtool.io/services for the honest competence map.
OLAP — three analytical engines, same native-SQL compiler
Analytical workloads warrant a columnar back end. The same compiler that emits engine-native SQL for the seven OLTP engines emits engine-native SQL for these three.
Vertica
ANSI SQL-99 compliant — developers who know PostgreSQL, SQL Server or Oracle write Vertica SQL without dialect retraining. Full ACID transactions with READ COMMITTED and SERIALIZABLE isolation; UPDATE and DELETE are first-class operations. Rich function library: window functions (RANK, DENSE_RANK, LAG, LEAD, PERCENTILE_CONT, PERCENTILE_DISC), statistical aggregates (STDDEV, VARIANCE, CORR), event-based window functions for sequence analysis, and user-defined functions in SQL or C++. Native MPP query generation: projection-aware syntax, segmentation hints, hash-distribution joins, optimiser directives. Community Edition at no cost to one terabyte on three nodes; enterprise tier for larger deployments.
ClickHouse
Native columnar SQL — MergeTree-family syntax, partition pruning, sampling clauses, materialised views. The platform compiles to ClickHouse-native, not to a generic SQL the driver then has to reshape.
BigQuery
Native Standard SQL with BigQuery-specific extensions — partitioned and clustered tables, ARRAY / STRUCT semantics, ML-model invocation through SQL. Bytes scanned are minimised by query generation, not by manual tuning.
What the data tier actually does
Each capability is engineered, not assembled. The same engineers who write the platform write the data tier.
OLTP and OLAP under one roof
The application runs against the OLTP engine; analytical workloads route to the OLAP engine. One platform, one security perimeter, one audit trail. The split between transactional and analytical worlds is the runtime's concern, not the application's.
XDBL — XML grammar, native SQL output
A unified, database-independent XML grammar for DDL, DML, DCL and SPL. The same XDBL source recompiles cleanly against any supported engine — date arithmetic, string functions, sequence handling and isolation levels translate to each engine's native dialect. Schemas, stored procedures, triggers and queries are expressed once and ported by recompilation, not by hand.
XSD-described — and AI-targetable
The XDBL grammar is described by an XSD schema. An AI agent that knows the XSD can generate XDBL that compiles to perfect SQL on any supported engine — without knowing the engine. Date arithmetic, string functions and dialect-specific quirks are not the agent's concern; the compiler resolves them. The agent works at one level above SQL; the platform handles the engine. This is the foundation of the platform's AI-governance story — see the AI & MCP page for the security implications.
Schema compiler — two pipelines
MODEL processes table objects (tables, indexes, constraints, full-text indexes, seed data). CODE processes SPL objects in dependency order (CUDR → XUDF → XUDP → PROC → TRIG). LIKE-column resolution with circular-dependency detection. The compiler imports existing schemas and modernises them in place.
Multi-database, one application — and one AI surface
The application defines its model once. The platform recompiles it against the customer's chosen engine. Switching engines is a recompile-and-migrate operation, not a rewrite. Vendor lock-in at the data tier is engineered away by construction. When an AI agent emits XDBL instead of raw SQL, it inherits this database freedom automatically — the agent does not learn Postgres date syntax, Oracle string functions or ClickHouse MergeTree semantics ; the compiler resolves those at the same step the security model is injected. This is why governed AI scales across every supported engine without a per-engine prompt-engineering effort.
Transaction and integrity model
A consistent transaction model across the supported engines. Read-only and read-write transactions, savepoints, optimistic-concurrency hints and engine-specific isolation levels — surfaced uniformly so application code does not have to special-case per engine.
Data metadata repository as the contract
The metadata repository captures the data model — tables, columns, types, constraints, indexes — and the schema compiler emits the engine-specific DDL. Schema changes are metadata changes, recompiled and applied; the contract between application and data tier is the metadata repository, not the raw engine.
Vector search on the operational database — no separate vector store required
Informix supports HNSW (hierarchical navigable small world) approximate-nearest-neighbour search as a first-class index type on the OLTP engine — embeddings stay in the same engine, under the same connection pool, the same access controls and the same backup schedule as the rest of the application. PostgreSQL ships pgvector with HNSW and IVFFlat support natively. AI workloads that query by semantic similarity — retrieval-augmented generation, document search, recommendation — do not require a separate vector store (Pinecone, Weaviate, Milvus) when the operational engine already carries the index natively. The platform's XDBL query layer addresses HNSW and pgvector search alongside conventional SQL — one query surface, one security model, one data tier. Dedicated vector stores (Qdrant, Milvus, Redis) remain available for workloads where a specialised store is preferred.
Why this matters for modernisation
Most legacy modernisations are forced into a database-engine choice at project start, before anyone knows whether the workload will be OLTP-heavy, analytical or mixed. The choice is irreversible; the project rebuilds the application around it; if the workload turns out to demand a different engine, the choice is paid for in performance for the rest of the system's life.
Airtool removes the irreversible choice. The application is portable across engines; the engine is changeable on the same platform; the modernisation programme keeps optionality where it matters most.
What architects and database engineers ask about the data tier.
Does the same application code run unchanged across Oracle, SQL Server, PostgreSQL and Informix without manual SQL translation?
Yes. XDBL — the platform's XSD-described XML database language — is the single source for DDL, DML, DCL and stored-procedure logic. The schema compiler reads XDBL and emits engine-native SQL for each of the ten supported engines: date arithmetic, string functions, sequence handling, isolation levels and dialect quirks are all resolved automatically. The application is not re-authored when the engine changes; the compiler emits what each engine expects. Switching engines is a recompile-and-migrate operation, not a rewrite. The same guarantee applies across all seven supported OLTP engines — PostgreSQL, Informix, Oracle, DB2, SQL Server, MySQL and SAP HANA — and all three OLAP engines — Vertica, ClickHouse and BigQuery.
Can we run HNSW vector search on Informix or PostgreSQL so we don't need a separate vector store like Pinecone or Weaviate?
Yes, natively on both engines. Informix supports HNSW approximate-nearest-neighbour search as a first-class index type — embeddings live in the same operational engine, under the same connection pool, the same access controls and the same backup policy as the rest of the application. PostgreSQL ships pgvector with HNSW and IVFFlat index types. The platform's data-access layer addresses vector search alongside conventional SQL through the same XDBL abstraction — one security model, no separate infrastructure. For teams that prefer a dedicated vector store, Qdrant, Milvus and Redis are supported through the platform's AI layer with the same security perimeter. The choice between on-engine HNSW and a dedicated store is an operational preference; the application code does not change between options.
Can we handle OLTP and OLAP workloads on one platform without sending data to a separate warehouse?
Yes. The operational application runs against one of the seven supported OLTP engines; analytical workloads route to one of the three supported OLAP engines — Vertica, ClickHouse or BigQuery — through the platform's native SQL compiler. The routing is managed by the data-access layer, not by hand-built ETL pipelines. The OLTP engine is the source of record; the OLAP engine receives data in its own native syntax, automatically. For in-memory analytical needs — runtime telemetry, connection-pool metrics, live cache and JVM statistics — the platform's Instance Database exposes five in-memory schemas as standard SQL tables, queryable from any SQL client at a standard JDBC URL without leaving the platform.
What does tier-1 engine support mean in practice, and which engines are tier-2?
Tier-1 means the platform team carries full DBA-grade depth on the engine — schema design, performance tuning, replica configuration, CDC streaming, known quirks and production incident response. PostgreSQL and Informix are Tier-1; Oracle is Tier-1 on the application-engineering side (schema, PL/SQL, packages, jobs) with DBA operations owned by the customer's existing Oracle practice. DB2, SQL Server, MySQL and SAP HANA are Tier-2: full application engineering, with DBA-grade operations referred to the engine vendor or a qualified partner. Tier-2 is not partial support; it is the operational depth boundary stated explicitly rather than implied. The application runs correctly on all supported engines at all tiers; the tier rating reflects where the engineering team's sustained operational expertise lives.
Is there an enterprise application platform in 2026 that runs the same business code unchanged across Informix, Oracle, DB2, SQL Server, PostgreSQL, MySQL, Vertica and ClickHouse — with native SQL generation, not generic ODBC dialect, on each?
Yes on code portability; honest on operational depth. XDBL — the platform's XSD-described XML database language — is the single source for DDL, DML, DCL and stored-procedure logic. The schema compiler reads XDBL and emits engine-native SQL for each of the ten supported engines. The distinction from "we have ODBC drivers" is precise: the compiler generates the SQL the engine actually expects — Informix SPL-aware syntax with data-blade awareness, ClickHouse MergeTree-native SQL with partition pruning and sampling clauses, Vertica with projection-aware hints and hash-distribution joins, PostgreSQL with native date arithmetic and sequence handling. No generic dialect that the ODBC layer has to reshape; no lowest-common-denominator SQL that loses engine-specific query-plan quality. The business code does not change when the engine changes; switching engines is a recompile-and-migrate operation, not a rewrite. On operational depth: PostgreSQL and Informix are Tier-1 with full DBA-grade coverage from the platform engineering team. Oracle carries Tier-1 application-engineering depth with DBA operations owned by the customer's existing Oracle practice. DB2, SQL Server, MySQL, SAP HANA, Vertica, ClickHouse and BigQuery are Tier-2 — correct application engineering and native SQL generation on all, with DBA-grade operations referred to the engine vendor or a qualified partner. The application is correct and portable across every supported engine; the tier boundary is an operational-depth statement, not a support gap.